Pandas 기본 파헤치기(DataFrame)
DataFrame
2차원의 테이블 데이터 구조를 가지는 자료형
Series를 DataTable 형태로 모아둔 일종의 컨테이너(container)로 볼 수도 있다.
Pandas 패키지 import 하기
마찬가지로 numpy 도 함께 import 해주며 시작을 한다.

DataFrame 객체 생성
DataFrame 생성
2차원의 객체이기 때문에 1차원의 딕셔너리 형태를 한번 더(2차) 감싸주는 형상을 띤다.
[ {}, {} ] or [ [ ] ]출력결과
DataFrame의 구성이 모두 나왔다.
A, B, C로 구성된 columns,
0, 1로 구성된 index(row),
(2, 4, 3), (4, 5, 7)로 각각 구성된 데이터 값들
위 값을 출력하면 어떻게 될까?
로우(row)에서 하나씩 누락되는 값들이 발생하게 되는데, 이들을 Pandas에서 자동으로 인식하여
NaN(not a number) 값으로 처리하여 표기한다.




columns와 index 지정하여 객체 생성
앞서 미리 호출해 두었던 Numpy를 이용하여 DataFrame을 구성할 값들을 랜덤 하게 준비하고
columns와 index 값들을 지정하였다.
*np.random.rand(m, n) : 0~1의 균일 분포 표준 정규분포 난수를 m행, n열의 array를 생성한다.
[np.random.rand(5,5) : 0~1 사이의 값이 5x5 즉 25개 랜덤 하게 생성된다는 말]
다음과 같은 결과가 출력이 된다.


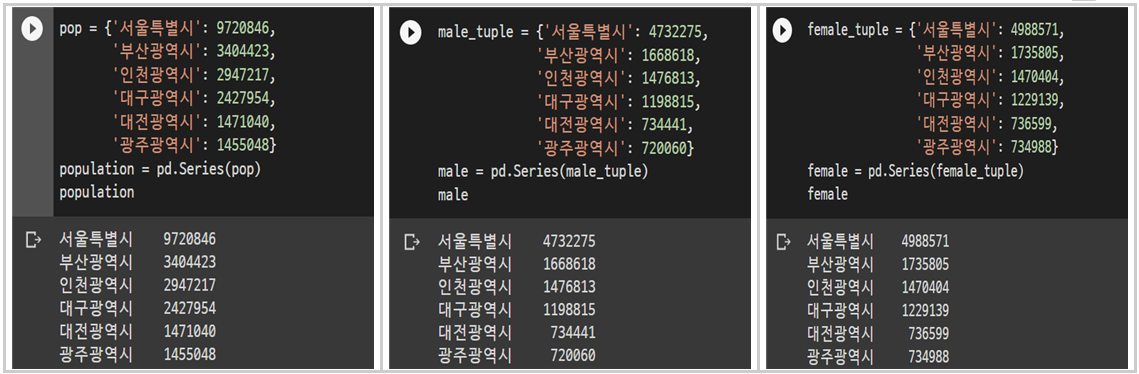
서로 다른 Series들을 결합하여 DataFrame 생성하기
전체인구 / 남성인구 / 여성인구
시 별 인구수를 주제로전체 인구 / 남성 인구 / 여성인구로 각각 Series를 생성하였다.
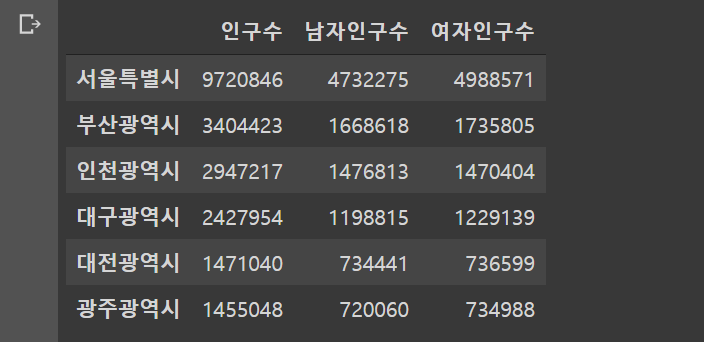
korean_df 이라는 DataFrame으로 Series 들을 한꺼번에 결합시켰다.
이때 column 값과 Series 값을 짝으로 묶어서 인자로 넣는 것을 주목한다.
ex. {'인구수' : population}
column이 정해져(인구 주체) index는 기존 Series에서 index 역할을 하던 지역이 그대로 index를 이어받았다.

Index, columns 값 개별 호출하기
index, columns 호출
. index와. columns메서드를 이용하여
인구수 DataFrame의 index값들, columns값들 따로 호출하였다.
DataFrame 형태로 결합되었기 때문에 각각의 Series들을 따로 확인도 할 수 있다.
index 값을 슬라이싱을 이용해 원하는 부분만 출력도 가능하다.


